The map of the world is constantly changing as new businesses open and others shutter their doors. Often, business closures are difficult to capture via traditional methods of capturing point of interest (POI) data, leading to inaccuracies in the databases. To solve this challenge, the FSQ/Places Insights team is excited to introduce our improved Closed model.
Powered by the rich features now made possible by our integrated POI dataset, the model learns associations that allow us to verify whether a POI is actually open or closed, such as:
- Does a business have the word “closed” in a business directory and is lacking check-ins for the past six months?
- Does the business have any Foursquare photos from the past year – and if not, have we seen similar activity on other sites?
- The rollout of the new model and closed buckets ensures that our FSQ/Places customers are getting the high-quality, relevant data they need in a form that is easier to work with than ever before.
Read on to learn more.
Making it easier to get the data you need, faster.
The new Closed model is internally represented by numeric predictions (values between 0 and 1) which are translated for users to bucketed labels (VeryLikelyClosed, LikelyClosed, Unsure, LikelyOpen, and VeryLikelyOpen). These labels make it easier for customers to leverage the model’s outputs and get to the data they need quicker. Developers, product teams, and users alike can create comprehensive filters and select the subset of data that’s more appropriate for their use cases.
Already, the new model and closed bucket are proving extremely effective at identifying permanently closed businesses. Indeed, our new models have identified almost 700,000 new permanently closed restaurants in the US alone that developers and clients can now filter out from their analyses and downstream products. In some of the recently released countries, our models can identify almost 50% more closed places. In addition, the new model boosts our ability to confidently identify open places too. In the US, both the precision and recall on open places show increases around 20%.
Armed with such high-quality POI data, developers and enterprises can conquer numerous challenges, including:
- Understanding competitor location density when considering new market expansion
- Transaction cleansing: improve location match and classification percentage of customer transactions (in the US or internationally)
- Power accurate navigation and POI search to build great user experience
Combining the top two POI databases – then building something even better.
When Foursquare and Factual merged in 2020, both companies were already aware of the challenge of identifying closed POIs in their respective databases. Factual’s machine learning model, Existence, used only third party data crawled from the web and sourced from data partners. It also combined the concepts of reality (does this POI represent a real-world place that can be visited?) and closed (is this POI closed?). A rideshare app, for example, may want to navigate to places that are closed but not to places that aren’t real – such as businesses that have moved or been replaced by another business. Existence gives closed POIs and fake POIs the same score, making it difficult for our customers to use.
On the other hand, while Foursquare’s existing approach utilized user edits and check-in data, it didn’t leverage other available firmographic data. With the introduction of the integrated Places dataset, it was clear to the Places Insights team that neither approach was ideal moving forward, and they needed to create a new Closed model that could identify closed places in the combined Places dataset.
By building new models on top of the integrated dataset, the models can leverage information from both legacy Factual’s significant web crawling capabilities, as well as Foursquare’s global user base.
How it works
A machine learning model is only as good as the data used to train it – so we created machine learning pipelines to predict the closed scores in an automated and scalable manner, putting particular effort into how we collect labeled annotations for training and how we engineer predictive features.
Collecting annotations
We designed a sophisticated stratified sampling methodology to collect samples of POIs for annotation. The methodology creates mutually exclusive strata for us to sample POIs based on high-level indications of open/closed status and combinations of POI attributes (e.g. single- versus multi-sourced, individual business versus chain).
This allowed us to create training data sets that both are representative of the general population and also cover specific groups and categories of places that are either challenging or of high interest to users. A dedicated team prepared high quality labeled annotations of closed/open places for training and for evaluation purposes.
Feature engineering
For feature engineering, we took advantage of the extreme variety of data sources and signals available in the integrated dataset and created over 3,000 different features for our predictive models to choose from. These features range from firmographic information we get from multiple third party sources to unique dynamic and time sensitive user generated signals, like visits, check-ins, edits, tips (reviews), and photos. We use elaborate feature selection techniques to identify features with high predictive power and low intra-correlation to avoid redundant information.
Model training and evaluation
We train multiple classification models, like XGBoost, with different hyperparameters to find the ones that optimize our performance criteria for different countries. We evaluate our models using continuously refreshed and growing hold-out ground truth data sets. This ensures their quality in predicting both open and closed status and identifying opportunities for improvement.
Take a look!
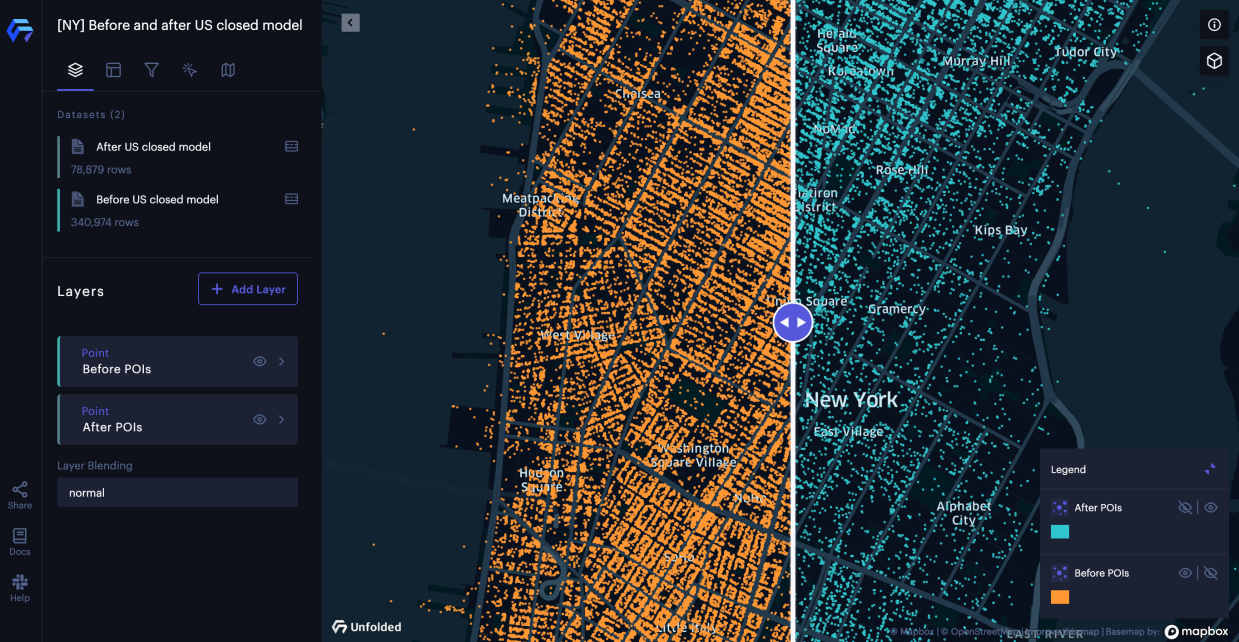
Before / after
Here are some maps (built on our Unfolded Studio) to show the distribution of open places in our dataset where the before is based on previous legacy filters and the after is based on new quality filters that incorporate integrated data and new closed bucket values. Of note is that there are many fewer after places because we were able to better filter out spam and closed POIs.
Want to learn more?
We’ve already released the Closed Model attributes for the United States and are constantly expanding coverage to new countries. At the time of writing this blog post, the new Closed model has been released for 18 priority countries and new countries are added in the coming weeks.
For more information about the new Closed Model or about our FSQ/Places products more generally, reach out using the form below.