Getting point of interest (POI) data right is hard. In addition to collecting the data on each venue, it’s critically important to validate that data for accuracy. Of course, the world is also constantly changing (due in no small part to forces like the COVID-19 pandemic)…meaning data about a place or venue could be outdated in a matter of days or weeks.
At Foursquare, we pride ourselves on developing and maintaining the most accurate, fresh, rich-in-detail, and accessible POI dataset in the industry. Our approach is unique: Foursquare’s in-house platform and curation process (which involves humans and machine learning) allows us to manage billions of references, identify the most appropriate for each attribute, and format everything in a manner that is easily accessible to our partners and customers as quickly as possible.
How do we do it, you ask? We’ll get to that, but first, it’s important to understand what factors you should consider when selecting a POI data provider or partner:
Freshness:
The world is in constant change—in the past year and a half, we have experienced accelerated shifts in businesses, with places opening or closing almost weekly. Constant awareness of these transformations and real-time updates is essential for customers and crucial in maintaining data freshness.
Variability:
Whether it’s seasonal variations or hours of operation—many attributes within data sets are ever-changing. All of these details generate an impact and, to ensure accuracy, all parts within a POI need to be current.
Big Data:
Due to the amount of information (Foursquare, for example, works with 100+ million points of interest across 200+ countries), there’s a lot of juggling data, matching it, and making sure we choose the correct values.
Subjectivity:
Meaning can still vary depending on the user’s preference and needs, despite the standardization of information. For example, a consumer can put importance into just the type of business (a restaurant) or the specific type of business (the type of cuisine of that restaurant), changing the meaning of the data and making us decide the best source for each situation. Another aspect of subjectivity is names and addresses—even though these are pretty straightforward, they can still vary depending on the location. For example, when talking about Central Park, the address is up for debate.
Container Relationships:
These are POIs found inside of other POIs. For example, shops and restaurants that are located inside of a mall. This information about complex relationships is necessary to represent the points of interest correctly in the data sets.
Scale:
There’s always a possibility of finding a small number of POIs with an issue. When encountering these, we need to consider scale—we’re working with data from 190+ countries and 50 territories, 900+ venue categories, 2.4M POI updates monthly from ground truth sources, so expecting 100% perfection is not realistic.
When it comes to building the best POI data sets, you need quality. And quality control is a never-ending process—for instance, our technology receives billions of inputs daily from consumers, the web, and 3rd parties.
Here are the steps we take to gather and filter that data for the best quality possible:
Aggregate:
In this step, we gather and curate verified data sources (100k unique sources and ~3 billion individual references that are updated continuously) to ensure a comprehensive representation of the real world. We collect our data from these four main places:
- Open Web Crawl: Large amounts of the data come from web crawl—including directory websites, chain locator pages, and anything in between that might have useful places location data.
- Human-curated: We combine our human-curated data from the Foursquare City Guide, Swarm community, and an outsourced team that helps us clean targeted POIs that we want to acquire or improve.
- Third-Party: Third-parties will license data to Foursquare in areas that we don’t have great insight or access to (and other proprietary information we can make use of).
- Verified partner contributions: We get data from verified data representatives for small and large businesses around the globe.
Extract and Clean:
Billions of raw data points are extracted, structured, cleaned, and validated—we’ve been doing this for over ten years allowing us to have a global view.
- Extract: The extraction part is just taking the data and extracting whatever bit of text the reference is using to assign a category in their taxonomy and map that reference directly to our taxonomy.
- Clean: We pull raw data from many sources, so we need to ensure we get it as clean and standardized as possible to start grouping them. To do this, we use a combination of human ruling and ML models at every step along the way.
When talking about billions of references, there are a million ways humans can refer to them. We go through the process of identifying the ones that mean the same and grouping them—for example, a pizza restaurant can be described as a pizzeria, pizza place, Italian restaurant, etc.
Clustering:
We clean non-unique data points to summarize them into unique and accurate POI entities. The clustering step determines which points of information from all different references talk about the same place. To understand this step better, think about trying to cluster geometric shapes—the easiest way to do this is by separating them by how many sides they have (without focusing on any other details such as color or size). We do the same thing with data but in a much broader and larger context. This is arguably the most important part of the process—if we get this wrong, we have many issues with the data, such as duplicate rows and overfold.
Summarize:
In this step, we determine how to present each reference. To do so and ensure accuracy, we assign a confidence score to each attribute value within the same cluster. With most core attributes’ confidence scores, we sum them, and the highest weighted score chosen is the correct representation for that POI. Other attributes such as latitude, longitude, and our calculated scores have their own, more complex summarization models. Let’s take people referring to the same store in Santa Monica as an example—we need to understand that maybe this same reference is represented slightly differently by each person and determine the form of the name that we would want to surface to customers. We also have multiple references regarding the location of the store—are they giving us the roof as a location? The front door? the back door? To ensure accuracy, we use latitude and longitude in a map. We do this across all of our attributes to variant degrees.
Quality assurance:
Quality checks are performed throughout the process to measure accuracy. To evaluate data changes, we use a combination of automated QA workflows and human verification and curation. These flag regressions of any significant changes to entity and input counts, attribute fill rates, and distribution shifts in categories and calculated scores.
What makes our proprietary technology platform unique?
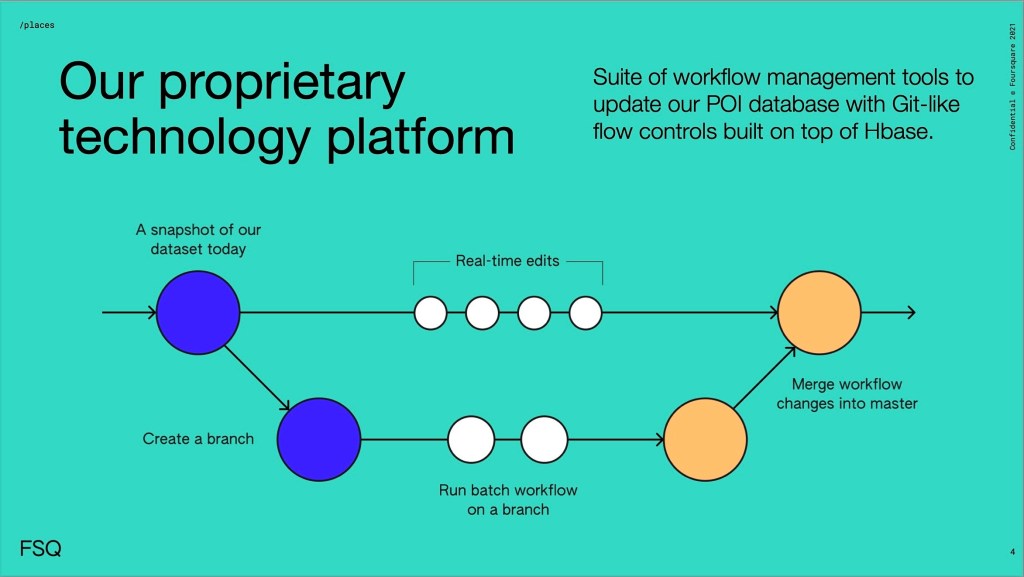
The use of branches:
‘Branches’ allow multiple people to work simultaneously without conflict. Our platform merges edits smoothly, preventing overwriting or conflicting edits. After QA (to ensure all changes are accurate), we merge all branches into the original timeline.
Non-conflicting real-time edits:
We can do as many real-time changes as necessary without starting a branch—our platform prevents conflicts when merging was already or actively added to a branch and any real-time changes made.
In short: our technology platform offers the best version of the data and the ability to move quickly, seamlessly, and to publish daily.
The Places data pipeline is designed to deliver accuracy and deep context, providing customers with a complete picture augmented with real-world context. Whether accessed via one of our partners (such as Amazon Data Exchange, Snowflake, CARTO, and Korem) or directly from Foursquare via flatfile or API, you’ll find the process of procuring and utilizing our POI data in your preferred, supported environment to be easy and rewarding.
Want to learn more about our approach to building the most accurate places data sets and how we use our technology platform? Get in touch with Foursquare today using the form below or check out our API documentation.