At each stage of rapid technology expansion and adoption, one can identify core open source software that led to significant leaps forward for both individual companies and entire markets. Even today, at the cutting edge of Artificial Intelligence (“AI”) one can observe the active role that open source is playing both in the construction of frontier models (using frameworks such as Tensorflow, PyTorch and the like) and in making these models available for wide use (eg Stable Diffusion, Meta’s LLama models or xAI’s Grok). Without open source initiatives, many of our favorite products would likely not exist nor would they work in parallel across multiple platforms enhancing the user experience.
Since our founding in 2009, we here at Foursquare have benefited greatly from open source. In our software development, we have been able to more efficiently innovate by leveraging generalized open source capabilities like Kafka for data streaming, PyTorch for machine learning and Apache Iceberg for data storage. Our geospatial capabilities are enhanced through specialized tools like Uber’s H3 indexing system, Apache Sedona’s spatial framework and OpenStreetMap’s (“OSM”) comprehensive mapping data. Unfortunately, in geospatial, location, and mapping software the data layer remains largely the provenance of large scale proprietary systems. The walled garden nature of the data layer greatly hampers the industry’s ability to go from strict specialization to generalized adoption, and it is in the general adoption layer that the real value to customers exists.
In an effort to change that dynamic, we are announcing today the general availability of a foundational open data set, Foursquare Open Source Places (“FSQ OS Places”). This base layer of 100mm+ global places of interest (“POI”) includes 22 core attributes (see schema here) that will be updated monthly and available for commercial use under the Apache 2.0 license framework.
In this blog, I will outline why we believe open source POI is critical to the development of the ecosystem, why Foursquare believes it can provide the foundational layer for open source development and how you, the community, can participate.
Why Open Source Places?
It is reasonable to ask, why a company like Foursquare who has spent years building a proprietary dataset would freely open a layer of that data to the community. So reasonable in fact that many of my colleagues thought I had lost my mind when I shared the news that we would be open sourcing our place data. We will return to that, but let’s first understand the importance of having an accurate global database of POI in the first place.
As we enter a new frontier of technology innovation that connects computer systems to the physical world (also known as Spatial Computing), a mission critical layer is helping these systems understand their context — in-part or in-whole — relative to physical places. This makes having a comprehensive and accurate understanding of the surrounding world foundational to the technology, otherwise your autonomous system may navigate to the wrong drop off point or your augmented optical experience may hallucinate resulting in poor customer experiences and so on.
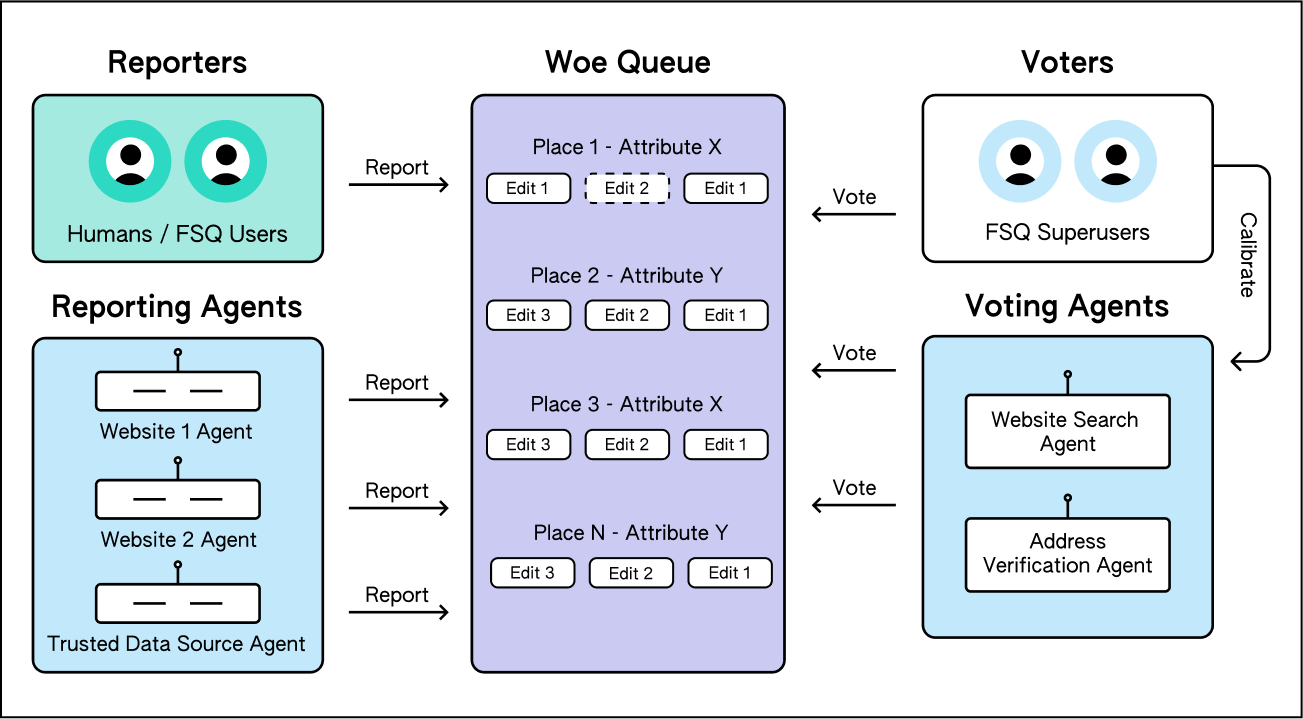
With that in mind, let’s now consider the challenge of creating and maintaining a real-world-synced place database. As our CTO Vikram Gundeti detailed in a recent blog on our newly re-launched Place Engine, to do this well requires an operating system powered by human-in-the-loop confirmations harmoniously orchestrated with cutting edge digital discovery systems to actively curate a database representative of the current world. In short, building an accurate global database of POI is an extraordinarily difficult task both from a technical perspective and from a capital resource perspective.
This leads to our belief that, absent a global proprietary distribution platform like Google Maps, building a comprehensive and accurate base layer of place data is indeed a problem best solved by an open source community.
Why Foursquare’s Approach to the Problem?
While we acknowledge other efforts to solve this problem, we view the likelihood of success as quite low with respect to global place data given the approach we observe is more akin to a data federation than an open source community. Our view is the likely result being to amplify the Digital Echo Chamber effect that we frequently observe in geolocation data.1
From first principles, we believe that any global place operating system requires the following three key ingredients or requirements to succeed:
- A cohesive and comprehensive place operating system
- AI contribution at scale (which requires significant tooling)
- Confirmed by human contribution at scale (also requiring significant tooling)
At the core of the FSQ OS Places effort is our newly launched Place Engine built on the three principles listed above and summarized below (for more details visit here):
Foursquare Place Engine: first of its kind, crowd sourced system where humans and AI agents collaborate to keep the places data in sync with the real world.
Builders Wanted
With the announcement of today’s release, you can now download the latest version of FSQ OS Places, but that is not all. Coming soon, we will be opening our community contributor tools where you can join the mission of creating the world’s most comprehensive and accurate base data set as a FSQ Placemaker. Follow this link to join our Placemaker waitlist and for future notifications about the project.
As part of this effort, we are committed to growing the ecosystem in partnership with the wider development community. Stay tuned for more ways to access and use the data as well as new projects that we will open source for community contribution (eg core machine learning models).
We look forward to seeing the innovation ahead.
Download the latest version of FSQ OS Places
____
Footnote:
- From Vikram’s previously mentioned blog, this Digital Echo Chamber “phenomenon occurs when location datasets are published online and subsequently used by other companies to create new datasets, often in combination with the original sources. This cycle repeats, with each iteration affecting future datasets. As a result, data provenance becomes unclear, and errors can spread across multiple datasets. This issue is especially concerning with the rise of advanced technologies like Large Language Models (LLMs), which make web crawling for structured information more efficient. As these technologies become more common, the risk of spreading unverified, inaccurate data grows significantly.” ↩︎