Getting point of interest (POI) data right is hard. In order to maintain the utmost accuracy in our Places dataset, we tackle tough problems on a daily basis, aggregating billions of inputs from multiple sources, including first party user-generated content from millions of consumers, ground truth datasets, web resources, and verified data partners.
One key problem we take on is matching and deduplicating updates to POIs from different sources, where raw data can contain noise, unstructured information, and incomplete or inaccurate attributes. We do this by combining our proprietary machine learning algorithms with human verification by a dedicated community of Superusers.
This summer, we challenged data scientists around the world to do this themselves, putting their modeling skills to the test to accurately match 1 million updates to POI in a machine learning competition on Kaggle.
Here’s how it worked: We provided a simulated dataset of 1 million pairs of updates to POI, fabricated to resemble Places that may match on a global scale, coming from different sources of varying levels of quality. Each pair included attributes such as names, street addresses, and coordinates. Competitors on Kaggle, the world’s largest data science community, were tasked to correctly identify which pairs “match” or represent the same POIs in the physical world, giving them a taste of the challenges we tackle every day here at Foursquare.
“We were so excited to see Foursquare hosting a data science competition on Kaggle. Right off the bat, it was clear that our community was eager to dig into the problem and dataset at hand, sparking some great discussions. After the fact, many competitors expressed to us that they learned a lot from this competition and had fun solving it, often requesting another competition from Foursquare. It was fascinating to see the different approaches the Kagglers took. Both the Kaggle and the Foursquare team were very impressed with the level of innovation. ” – Addison Howard, Kaggle
The competition drew a total of 22,050 submissions from 1,290 data scientists. Competitors came from across the globe, with teams topping the leaderboard from New York, Paris, Honolulu, Zurich and Shanghai. Teams continually refined their models to improve their accuracy, with some teams submitting more than 300 models, as Kagle’s algorithms calculated the winners in real-time.
We’re excited to spotlight the data science aficionados who trail-blazed their way to the top of the leaderboard:
Philipp Singer utilized NLP deep learning models
Philipp Singer is a Senior Data Scientist at AI/ML software company H2O.ai in Vienna, Austria. Singer earned his PhD in Computer Science at TU Graz and conducted his postdoc research in Germany. He has profound experience in ML research and applications and is a top ranked ‘Kaggler,’ (noted as a ‘Competitions Grandmaster’), participating in 58+ competitions and previously ranked #1 on the entire platform.
For our competition, Philipp had a two-stage approach that utilized NLP deep learning models. The first-stage model was a metric learning model with ArcFace loss trained on the original input data predicting the point-of-interest of a record and consequently putting similar records into a similar embedding space. The second stage additionally trained a bi-encoder NLP model based on the proposed candidates from the first stage. His final submission blended both first- and second-stage models. He noted that he “learned a lot in this competition and [was] very happy to have solved it with deep learning only. It is most fun to me personally, and I am sure this general approach will come in handy again in the future.”
Yuki Uehara used Graph Neural Network
Another top contender was Yuki Uehara. 22 years old, Yuki is currently enrolled as a senior at the University of Tsukuba in Japan, focusing on Mathematical Optimization Machine Learning. He’s a Kaggle ‘Competitions Master,’ having participated in 18 Kaggle competitions to date.
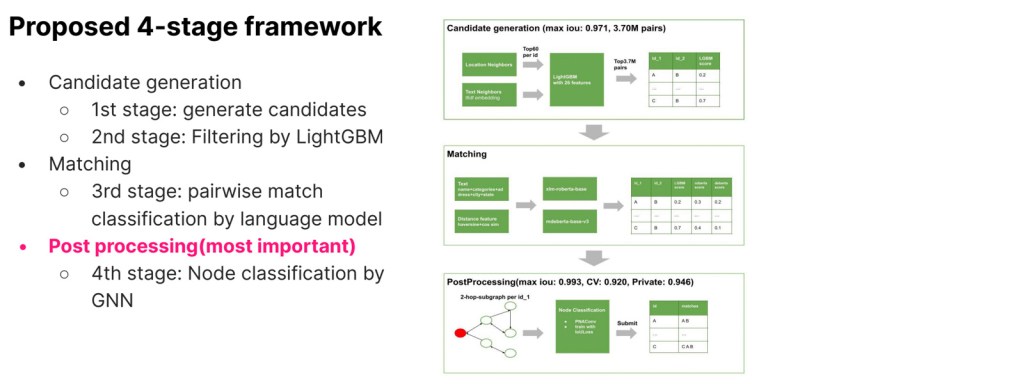
Yuki proposed a four stage framework for our competition, involving generating candidates based on text similarity and geographic proximity; filtering by LightGBM; pairwise match classification by two transformer language models; and most importantly, post processing node classification by a Graph Neural Network (GNN). With this framework, he was able to improve his score from 0.907 to 0.946. Many other competitors commented on how impressive and unique his approach was.
Team re:waiwai iterated and improved
One member of Team re:waiwai was Takoi, a Data Scientist at Rist based in Kyoto, Japan, and a ‘Competitions Grandmaster,’ having participated in 41+ competitions and previously ranked #17 on the platform. He worked with Pao, a Data Scientist at ABEJA in Tokyo, Japan, a ‘Competitions Master’ who has participated in 33 competitions to date. The final member of the team was Charmq, an Engineer at Preferred Networks in Tokyo, Japan, a ‘Competitions Grandmaster’ previously ranked #12 on the platform.
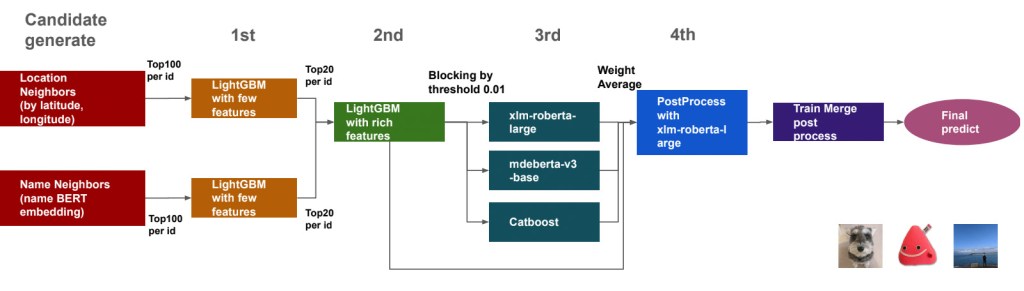
This team proposed a three stage model process, in addition to a fourth post-process and xlm-roberta solution. In the first stage, after they generated candidate matches based on text similarity and geographic proximity, they created a LightGBM model with limited features to further reduce the number of candidates in a memory-efficient way. They then fed the top 40 candidates per id in the 2nd stage LightGMB model using an expanded set of engineered features, such as similarity features (Levenshtein and Jaro-winkler distances) and statistics/ratios, Euclidean distance using latitude and longitude, as well as embedding of name with SVD for dimensionality reduction. In the third and fourth stages, they added transformer BERT-based language models, and iteratively fine-tuned the models based on cross-validation and leaderboard results.
Team 2:30 balanced efficiency and effectiveness

Our next winners were Team 2:30. Yuki Abe and Tom Yanabe are both ML engineers at DeNA Inc., a mobile gaming and e-commerce platform based in Japan. (Tom is a Kaggle Master). Takami Sato is a PHD student in computer science at the University of California Irvine, who formerly worked at DeNA as well. They were joined by Kohei Iwamasa, a master student at Kyushu University in Fukuoka, Japan, and Takuma Ota, a data scientist and developer at an Edtech company in Japan.
The team’s solution involved first finding promising but still coarse-grained candidate pairs using geographic proximity and TFIDF scores. They creatively added a Transformer-based blocking stage to effectively reduce candidates while maintaining high recall. They then used an ensemble of gradient boosting decision trees (LightGBM and XGBoost) and BERT-based language models for the final predictions. Balancing efficiency and effectiveness was a key challenge, using only important features and tuning the size of the model (i.e. number of target points).
The takeaway?
Overall, we were incredibly impressed with the innovative solutions the Kaggle community came up with and found great inspiration in their work. Thank you to all who participated!
Want to learn more about how we maintain accurate, up-to-date point of interest data at Foursquare? Learn how we get POI data right.