My software engineering career began in 2004 at Teradata, a data warehouse company, where I worked on various components of the database stack. After two years, I transitioned to Amazon, spending the next 15 years focused on online systems. Two and a half years ago, when I joined Foursquare, I was reintroduced to the world of offline data platforms. Initially, I found it challenging to navigate the components of modern data platforms and the various players in the space. However, I soon realized that the elements of today’s data platforms are essentially unbundled, decentralized versions of the core components found in traditional data warehouses.
In this blog post, I’ll share insights from my journey of rediscovery. We’ll explore how data was processed using traditional data warehouses, examine how changes in the data ecosystem led to the evolution of processing systems, and investigate how these shifts paved the way for modern tooling.
Evolution of Big Data Systems
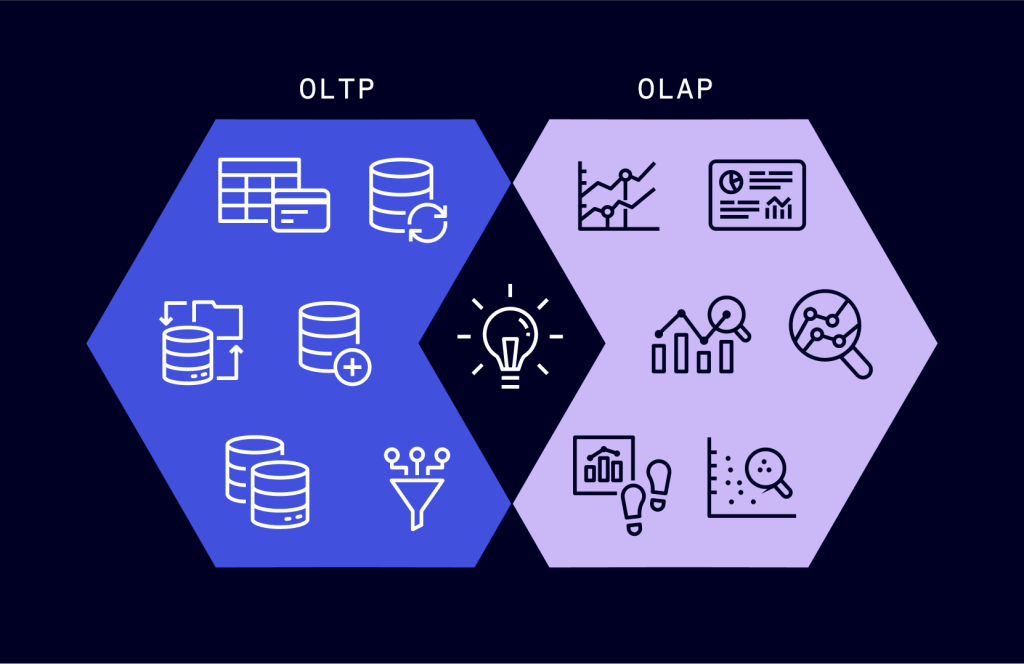
Traditionally, databases were classified into two categories: 1) OLTP (Online transaction processing) systems, which dealt with handling the online transaction oriented workloads, and 2) OLAP(Online analytical processing) systems, which dealt with the handling of the offline analytical workloads geared at generating business insights and reports. A simplistic difference between the two categories is the number of rows involved in the processing of a typical query. OLTP systems were write-heavy and processed a handful of rows at once, whereas OLAP systems were read-heavy and processed millions of rows per query.
In the late 2000s and early 2010s, we witnessed some monumental shifts in the technology landscape: a) Cloud computing brought down infrastructure costs through on-demand access to storage and compute, b) smartphones became ubiquitous, leading to an explosion of mobile applications and services. Data generation skyrocketed at an astronomical rate driven by factors such as the growth of social media, IoT devices, and digital transactions, and c) Artificial Intelligence and Machine Learning (ML) systems gained prominence, driven by advancements in algorithms, increased data availability, and improved computing power. This led to widespread adoption of AI and ML across various industries.
Traditional OLTP and OLAP systems could not keep up with this pace of change. OLTP databases were replaced by NoSQL key value stores that offered better performance without skyrocketing the costs. All the data captured through the key-value stores were dumped into optimized file systems for OLAP workloads, powered by newer computing frameworks such as the Hadoop & Map Reduce. This shift eventually led to the emergence of the concept of a modern data lake, a centralized repository that allows organizations to store all their structured and unstructured data at any scale. It provides a cost-effective solution for storing massive volumes of raw data in its native format until it is needed for analysis or processing. Compute systems like MapReduce and Spark operated directly on the data in the data lake using commodity hardware eliminating the need for specialized OLAP systems.
Years later, most of the tools and frameworks in the big data ecosystem are centered around a data lake and are decentralized re-imaginations of equivalent concepts in the traditional data warehouses.
Anatomy of a Modern Data Platform
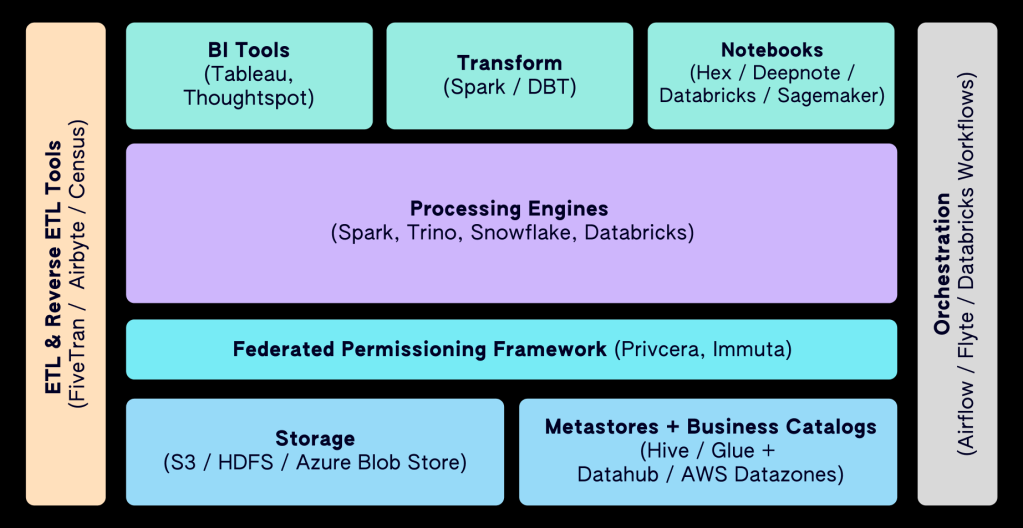
A traditional data warehousing system had the following components:
- A storage system, which stored data in a representation (typically in a columnar format) optimized for operations such as aggregation and summarization
- A set of system tables that captured the metadata about various user tables and a permissioning layer to manage access to different user tables and objects
- A query planning and execution engine, which translated user queries typically specified in SQL, created a plan of execution with detailed steps and executed them to return the results
- ETL processes which ingested data into the data warehouse from various sources and exported them into other systems such as CRMs and are typically orchestrated through cron
- A custom dashboarding/reporting solution built on top of the data warehouse for business reporting
- A command line or GUI based SQL editor to run queries for ad-hoc analysis
Now, let’s talk about how each of these aspects manifest in the modern data platforms.

Storage
Data in modern big data systems is typically stored in a distributed file system such as S3, Azure Blob store, or any HDFS implementation. The storage layer is also referred to as the “data lake.” Historically, data was stored in formats like JSON, TSV, or CSV, which were suboptimal for these workloads. Parquet and ORC, compressed columnar storage formats, evolved as the standard in this space, with Parquet getting a lot of adoption. Even with the adoption of formats like Parquet, several issues remained:
- Concerns like partitioning (storing data corresponding to a client or a date) relied on adopting specific folder structures within the root folder.
- Features like schema evolution and indexing, that were common to databases, were not available.
- These formats did not support granular updates. That meant we needed to rewrite the entire file to add updates.
- There were no tools for schema evolution.
To address the above concerns, open table formats such as Apache Iceberg, Hudi, and Delta were invented. These open table formats were implemented by adding a Write-Ahead-Log on top of underlying file formats (typically Parquet) and enabled several advanced features such as ACID transactions, efficient schema evolution, time travel and data versioning, improved indexing capabilities, and support for record-level updates and deletes. These open table formats have significantly enhanced data management capabilities in big data systems, allowing for more flexible, efficient, and reliable data storage and processing.

Metadata & Permission Management
In traditional databases, you have system tables which capture information about all the user tables, their schemas, and other metadata. One of the challenges with data lakes is discovery of datasets, as it is easy to dump data into the data lake and not have to worry about storing any metadata corresponding to them. Metastores address this particular problem: Hive, Glue, and Unity are the most popular meta-stores which maintain schema, location, and other information about the datasets stored in the data lake.
Then there are business catalogs like AWS Datazones and Datahub, which typically sit on top of the meta stores and provide a web interface for the business users to browse and attach additional metadata to the datasets in the data lake. These business catalogs typically have integrations with permission management systems that facilitate access management on top of the datasets in the data lake. Privcera and Immuta are stand-alone solutions that offer a federated permission management layer on top of the data catalog systems.

Query Planning & Execution Engines
A key aspect of the data lake architectures is the explicit decoupling of compute and store engines, thereby allowing the choice of plugging in different compute engines to operate on top of the same data. There are two classes of compute engines in the modern data ecosystem: a) those that do not create copies of data and directly operate on the data in the data lake, and b) those that load the data into their own optimized storage system for use.
In the first category, we have technologies like Spark, Presto, Hive, Pig, and Trino. These compute/query engines typically process user queries on managed cluster platforms like AWS EMR/Kubernetes/DataProc by loading data required from the data lake into these clusters. These compute engines typically also integrate with the meta stores to provide seamless access to the underlying data. Spark is by far the most popular framework for data engineers, as it supports two flavors: one that allows users to issue queries on data in SQL format and another that gives access to the lower-level APIs to directly process the data. Most of the other compute engines only support a SQL flavor. DuckDB is a unique in-process SQL warehouse that has been gaining a lot of traction due to its ability to process large volumes of data with a single node architecture.
In the second category, we have compute engines that follow the traditional warehouse pattern, which includes Snowflake and Redshift. These systems require data to be loaded from the data lake into their own optimized storage, sharded and partitioned in the appropriate way for access through SQL.
Each approach offers different trade-offs: direct operation on data lakes often provides more flexibility and can be cost-effective for large datasets, while loading data into optimized storage can offer better query performance for frequently accessed data. Some platforms, like Databricks’ Delta Lake, aim to bridge these approaches by providing optimized performance while still operating directly on the data lake.

ETL (Extract-Transform-Load)
Traditionally, ETL referred to processes which moved data from one system to another, typically transforming it along the way. In modern data platforms, we often see both ETL and ELT (Extract-Load-Transform) processes, where data is sometimes loaded before transformation. These processes are typically employed to import data into or export data out of the data lake, or moving the data from the data lake to a compute engine that requires data in its own storage system (such as Snowflake). Fivetran, AWS AppFlow, and Airbyte provide connectors to a variety of sources to facilitate data movement.
“Transform” in a traditional ETL sense, is about preparing data to be able to move them to a target system and typically involves some data cleaning and data type mapping. But transform also implies generation of derivative datasets within the same compute/storage system by applying complex algorithms or ML models. For instance, creating customer segments based on purchasing behavior and demographic data. For both cases, Apache Spark remains an industry standard, especially when it comes to processing large scale datasets. However, for those working primarily within data warehouses, SQL-based transformation frameworks such as dbt (data build tool) and SQL mesh are gaining popularity. Apache Flink and Kafka are the go-to options for processing streaming workloads.
Reverse ETL, a relatively new concept, involves moving data from data warehouses or data lakes back into operational systems. This is becoming crucial for operational analytics, enabling data-driven decision making across business functions. Census, Hightouch, and Rudderstack are examples of prominent examples of reverse ETL tools.

Orchestration
The ETL processes are typically scheduled through an orchestration system. A key concept in the orchestration systems is that of a directed acyclic graph (DAG) of tasks that need to be executed. Data pipelines which implement ETL processes are implemented as a DAG. This allows different tasks to be chained together in a particular order to achieve a specific output. These DAGs are triggered by specific events, such as a scheduled event or availability of specific upstream data. A critical feature of modern orchestration systems is data lineage tracking. This capability allows organizations to: a) trace the origin and transformations of data throughout the pipeline, b) understand dependencies between different data assets, and c) perform impact analysis when considering changes to data sources or transformations. Lineage tracking is particularly valuable in complex data environments where data goes through multiple transformations and is used by various downstream processes or applications.
While Apache Airflow and Flyte are leading orchestration systems, other popular tools include Apache Nifi, Prefect, and Dagster. Most major data platforms also include native workflow orchestration systems such as Databricks Workflows and AWS Step Functions.

Business Reporting
Historically, Business Intelligence (BI) reports were generated using custom tools. However, the landscape has evolved significantly with the advent of modern BI tools such as Tableau, Looker, Thoughtspot, Microsoft Power BI, and Qlik. These tools provide connectors that make it easier to build dashboards and reports directly on top of data in your data platform. Each of these tools has a unique approach to dashboard creation and data querying, often incorporating visual interfaces for data exploration and natural language processing for asking questions about the data.

Notebooks
Notebooks are a modern tool that evolved from various precursors, including SQL editors and scientific computing environments. They provide data scientists and analysts with an interactive environment for data analysis, model prototyping, and collaboration, combining code execution (in languages like Python, R, and SQL), text formatting, and data visualization. They are an essential element in modern data science workflows.
Jupyter is the most widely used notebook platform, supporting numerous programming languages. Other options include JupyterLab, Apache Zeppelin, and RStudio for R. Notebooks are available as hosted services (e.g., Google Colab, Hex, Deepnote) or embedded within data processing platforms like Databricks and Amazon SageMaker.
Choosing a Data Platform Strategy
Companies face a critical decision when building their data platform: adopt an all-in-one solution from vendors like Databricks, Snowflake, or AWS, or compose a custom platform using tools from different providers. All-in-one solutions offer seamless integration, simplified management, and faster time-to-value, but come at the expense of creating a potential vendor lock-in and increased overall costs. Custom-composed platforms provide greater flexibility and tool selection and potential cost savings. The trade-off is increased upfront integration complexity. The choice depends on factors such as in-house expertise, specific business needs, long-term strategy, and budget considerations. Some organizations may start with an all-in-one solution and transition to a custom platform as needs evolve, while others may prioritize flexibility from the outset.
At Foursquare, we faced this choice about a year ago and look forward to discussing our experience in a subsequent blog post. There, we’ll assess the path we chose and the reasoning behind our decision.
Subscribe to get our latest articles, event invites, reports, and more
Authored By: Vikram Gundeti