Part of what makes our apps, Foursquare City Guide and Foursquare Swarm, so supported by our users is the ability to surprise and delight our community. One of the many ways we accomplish this is by delivering timely and relevant push notifications such as what to do in the city a user just landed in, a suggestion to uncover a local gem in a new neighborhood, or what places a user might enjoy based on a food they have indicated interest in.
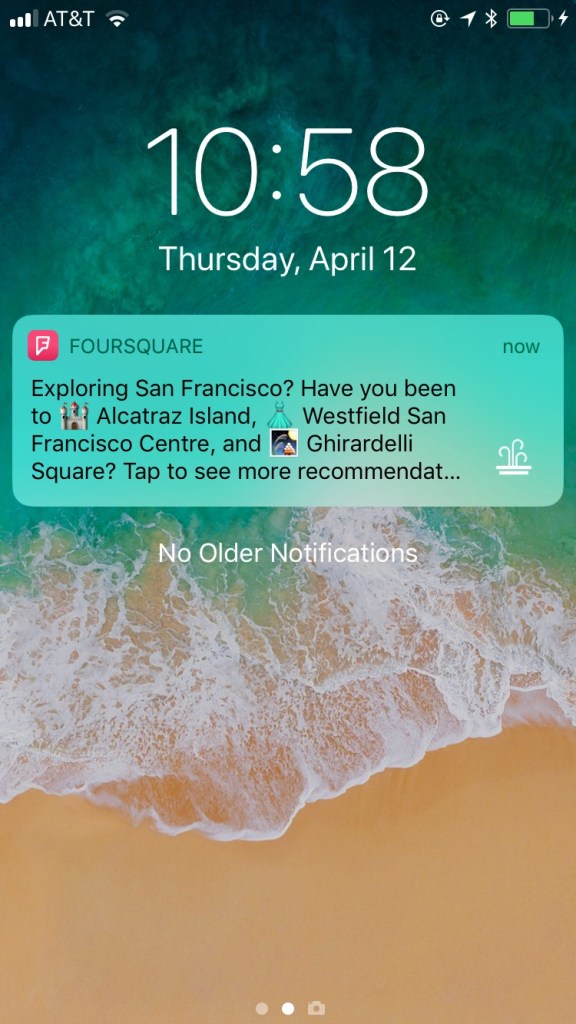
We send millions of these push notifications or “pings” every day. Although we have a few different mechanisms for sending pings based on various triggers (for example when a user has visited a place, we’ll send recommendations related to that place), this post will cover a system we call push recommendations. This system generates personalized pings using Hadoop MapReduce, and then uses this output to deliver interesting pings to users at targeted times throughout the day. Let’s walk through the backend of this together.
Life of a Ping
The entry point to all of this is our trove of data on the Hadoop File System (HDFS). On HDFS, we have nightly snapshots of our database collections as well as log data that is collected throughout the course of the day. Using these primary sources, we have a series of “candidate” MapReduce jobs (written in Scalding) that aggregate all of this information and come up with a list of users, who we think might be interested in a ping. Each candidate job corresponds to one type of push recommendation. For example, there could be one dedicated to finding users who have indicated an interest in a specific kind of food, like hot dogs or soup dumplings. Another example candidate set would be users who live near a restaurant that has recently opened.
At this stage in the process we have several different lists of users corresponding to different types of push recommendations. As mentioned earlier, we try to deliver push recommendations at specific times of day. For example, a ping about restaurants might be appropriate to deliver at dinner time — each type of push notification has optimal delivery dates and times. The next step is to convert the mapping of ➔ [users] into a map of ➔ [(ping type, user)]. When the data is in the latter format, we have a starting point from which, given an hour of the day, we will know which users to ping with which type of recommendation.
Now that we have this list of users keyed by hour of day living in HDFS, the next challenge is to use that information to send pings in a timely manner. For this task, we need to exit MapReduce-land and move into the world of our microservices. The base user/recommendation list is loaded in to our low-latency serving system quiver from which it will be accessible by online services. Then, we have a scheduling process that wakes up every hour, reads the list of users for that hour, and sends the appropriate push recommendations using a fleet of workers.
Generating Ping Content
When a push recommendation arrives at a worker, there’s still some logic necessary to convert it into a deliverable ping. Often the information that arrives will be sparse: just a user ID and the type of recommendation we would like to deliver. Next, we will fetch the appropriate data records and construct a localized message for the user using our in-house i18n framework. We also perform additional checks to make sure the recommendation is still timely and relevant.
We want to terminate the sending of a ping upon any kind of failure reason. If the real world prerequisite under which we generate the recommendation is no longer true, for example, the user un-liked the venue for which we generated the recommendations or the venue is closed, we do not want to send the ping. Additionally, we log any specific reasons by which a recommendation fails to be able to be sent, so we can diagnose issues with our recommendations.
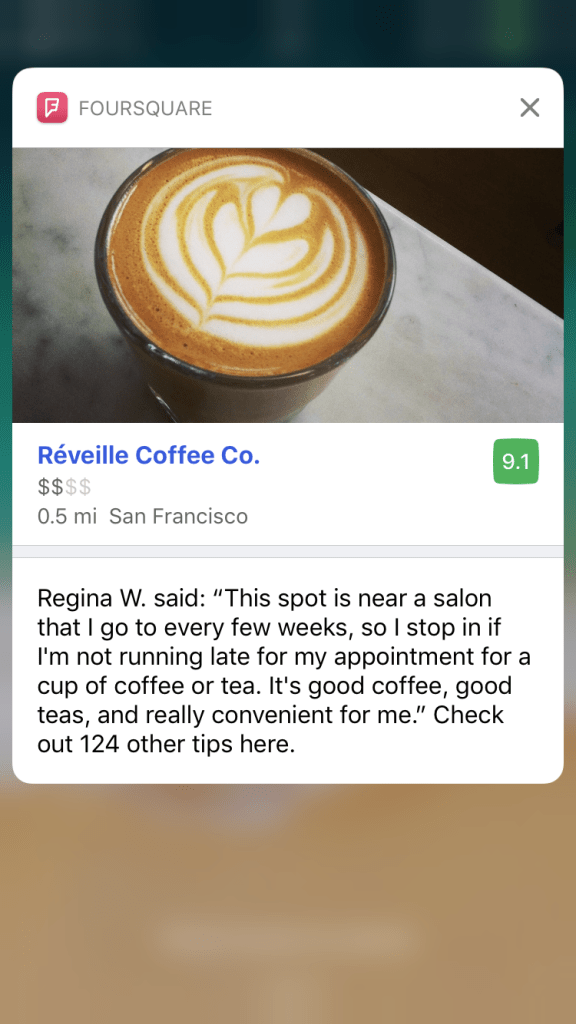
After generating the ping content, it’s time to package it up and deliver it to our users. In order to create the most engaging experience for our users, we attempt to render rich notifications whenever possible.
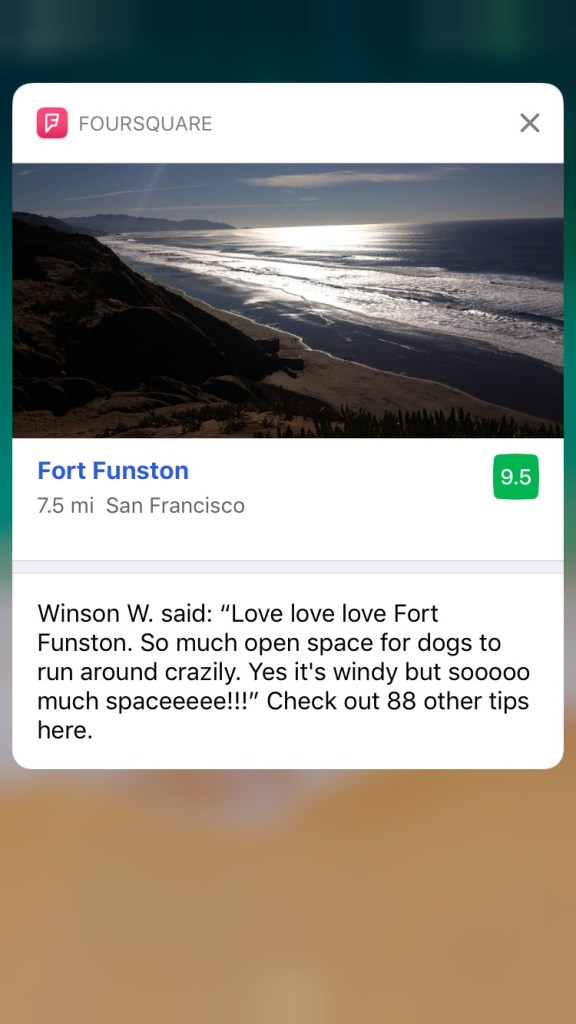
In order to provide the richest notifications possible, we would need to send a ton of data to the user’s device, which sometimes exceeds the data limit enforced by the mobile platforms. To get around this obstacle, we save the excess payload to an online cache and allow the users’ devices to fetch the extra data through an API endpoint. With our final step of ensuring the output has an appealing design, the ping finally reaches the user.
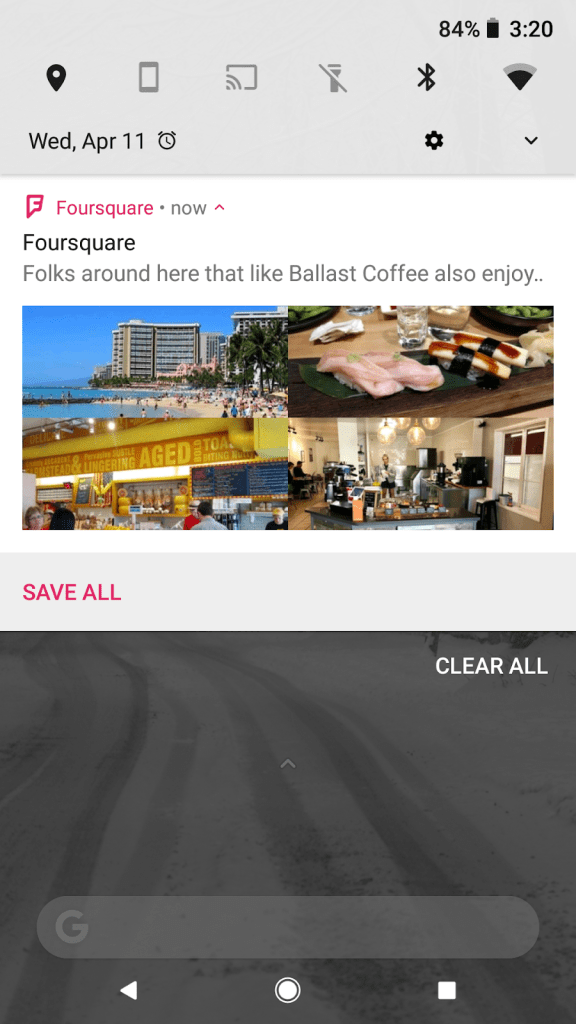
Final Thoughts
In this post, we covered our offline pipeline that generates “candidate” users for receiving push recommendations, as well as our online system that generates pings for these users. Structuring the offline system as a series of distinct candidate jobs that feed in to a centralized join (with dependencies modeled using Luigi) has allowed many engineers to independently develop new types of push recommendations. We’ve also covered how we develop online, end-to-end mechanisms to efficiently and reliably deliver enjoyable user contents.
If you’re interested helping deliver meaningful consumer experiences through geo-contextual location data, we’re hiring! Feel free to also check out our open source projects for a taste of some of the awesome projects we’re working on.