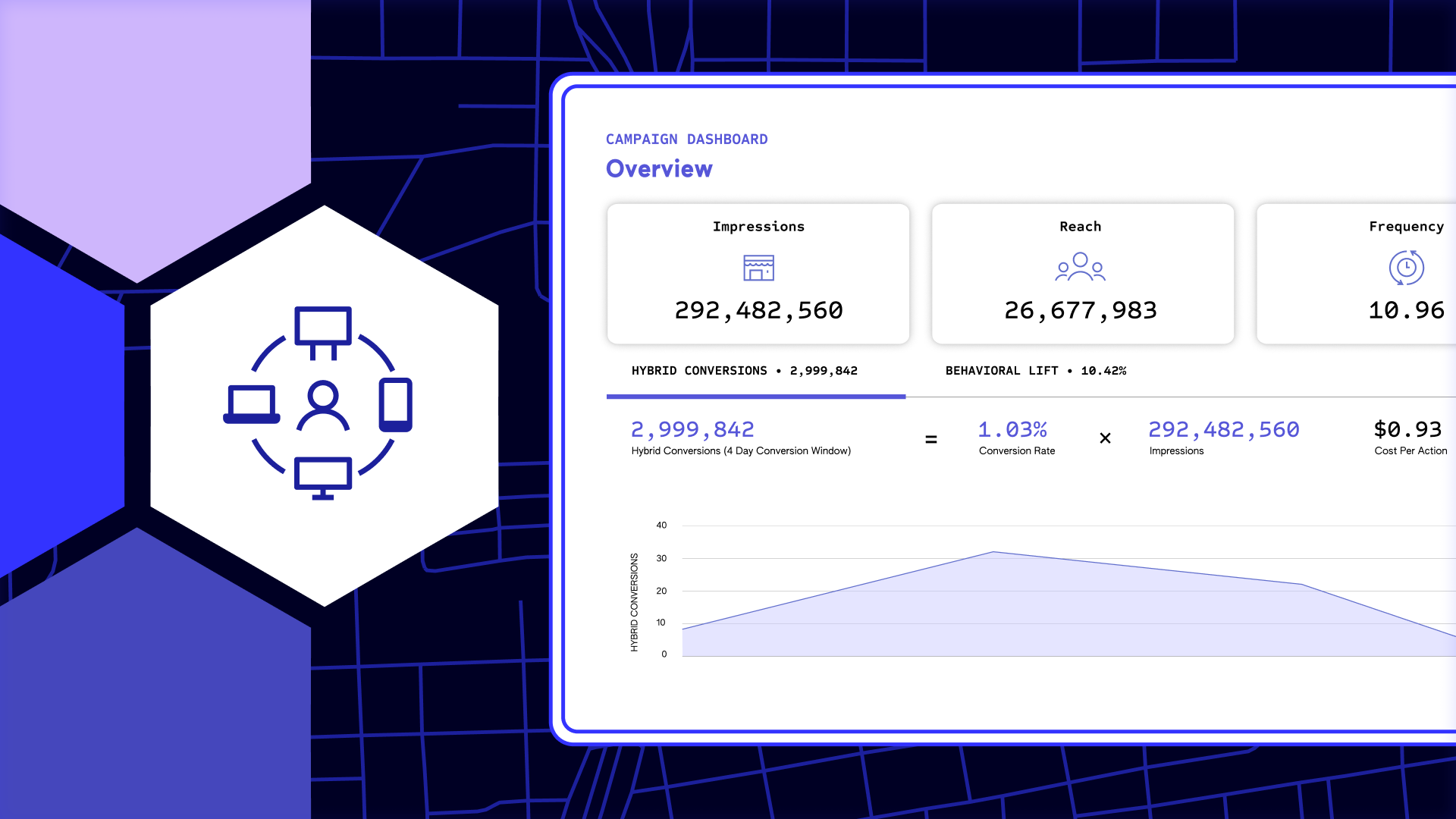
As any data scientist will tell you, the combination of increasingly large data sets and the varied data types have made yielding useful business insights a major challenge. Individual data sets have gotten so large and cover so many topics – believe it or not, there is now a dataset of 250 million coughing sounds – that they risk outstripping our capacity to use them effectively. The plethora of data types is no less a challenge. Something as seemingly simple as predicting what a gym’s peak hours will be depends on data covering the weather, local traffic patterns, whether local businesses have employees back in the office, public transportation usage, the health of the local community, and historical usage data, just to name a few.
There is yet another complicating factor: many companies’ data (including data they sell) is simply inaccurate. According to O’Reilly, only 20% of companies are taking the basic steps necessary to protect data quality. Many deal with crosscutting challenges to their overall data quality, from too many data sources, to too much inconsistent data, to the persistent “poorly labeled or unlabeled data” conundrum.
It’s no surprise, then, that IBM estimates bad data costs companies $3.1 trillion each year.
So, how should companies make good use of the data they’ve collected or paid for? How can they integrate countless large data sources to produce useful and relevant findings? As the Senior Director of Engineering at Foursquare, which has been helping companies make use of location data for over a decade, I’ve learned what works. Here’s how companies should integrate data to create real value:
- Ask the right questions to determine if your data is trustworthy. As anyone in this field knows, data that isn’t accurate isn’t valuable. Given that the decisions that organizations use data to make – from budget allocation to monitoring areas most likely to be hit by natural disasters – inaccurate data can do immense damage.
So how can you determine if the data you’re considering using comes from a trustworthy source? Ask yourself (or the source) some key questions – does the data provider publish their upstream data source? Does the data provider explain their methodology in generating its data? Does the data provider constantly update their data? If you can answer “yes” to these questions, the data provider is most likely trustworthy.
In addition to vetting the source, it’s also important to consider the quality of data. Constantly updating data is not just for data providers; it goes for data scientists themselves. A dataset that hasn’t been updated in years probably isn’t accurate, so it’s imperative to take that extra step and check. - Understand the objective first. Planning and asking the right questions prevents cumbersome cleaning on the back end. First, ask what you are trying to do with the data. Are you using it to make a decision? To prove a point to external audiences? Internal ones? What is the conclusion you’re really looking for here? How do we want this displayed? Not only will this help you to cut extraneous steps, but it will likely save you money on purchasing unnecessary data sets.
A clear objective makes project management easier and provides the rare opportunity to exceed expectations. If you know exactly what your organization is looking for, it’s possible to break down a conclusion into granular and specific details. For instance, if the ask is about behavioral patterns based on age, you can analyze the groups further, using demographics like career, marital status, even hobbies and interests. Different subgroups provide context and greater insight.
All this to say, don’t be afraid to over ask during initial planning meetings. The more information you have, the more time you save, and the better results you deliver. Remember, you’re the expert. So fill in the blanks and provide additional information that may prove helpful to achieve the objective. - APIs must join data sources to avoid unnecessary silos. Many APIs are only built to handle one data source and only one data type (i.e., weather data, traffic data, etc.), a system that is increasingly obsolete, and strenuous for data scientists working with increasingly larger sets.
To ease the process, avoid duplication errors, and save money, try choosing an independent, focused platform. Without conflict of interest, independent data companies can partner with multiple brands for easier integration and greater accessibility. When shopping for platforms, ask about partners. Challenge the sales team on any integration limits. Compare the many tools available and find one that accommodates the growing amounts of data you plan to analyze. - Make sure you and your team have the computing power to handle massive amounts of data. This is especially pertinent with the transition to hybrid work environments. Investing in good hardware gets you the most leverage out of your software. Luckily, SaaS platforms are becoming more accessible than ever before, with the ability to run on smaller workstations.
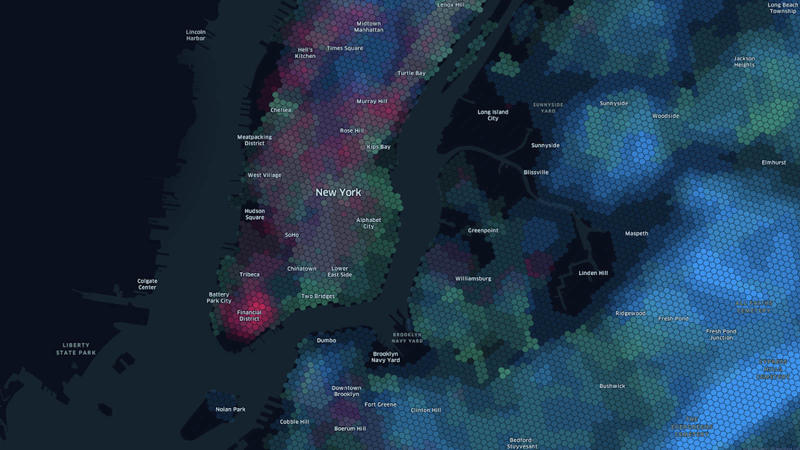
Internet speed is also a factor here. Make sure both your corporate and home office can keep up with real-time data updates necessary to remain competitive, particularly as the remote-work revolution appears permanent. Clean and update your hardware and browser regularly for space and speed. - For the most complex data applications, like data visualization, make sure the program you’re using can handle the load. Be ready to adjust tactics and programs depending on the information you’re seeking. For example, location data providers with large, diverse sets of POIs are preferred over competitors, as their platforms are inherently built to handle large volumes of information. Foursquare’s Hex Tiles system, for instance, allows for quick visualization of an immense amount of data, all within a normal browser. (Full disclosure: since I work at Foursquare, I’m biased towards Hex Tiles.)
Take full advantage of your program’s capabilities, and take time to explore the full range of tools and features. Don’t be too proud to make use of the helpdesk or to consult blogs, Reddit threads and other forums for insights into maximizing your program and unlocking hidden potential.
Data integration is a massive challenge. Yet it is not optional. Data analysis – and thus, quality data integration – is now a “must have” for major business decisions. It is difficult to get investment, or even C-suite signoff, without it.
There is no choice, but to use data to make key decisions, which means there is no choice but to use data right. Integration may be tedious, but it pays off.
Shan He is Senior Director of Engineering at Foursquare.